This is the first technical post in our new AI Research Lab publication where we will be chronicling the work of SingularityNET’s AI Team. The SingularityNET Research Lab will give you insider access to the most exciting AI initiatives we have under development. When launched, these services will only be available through the SingularityNET platform.
Bridging the Gap: Allowing AI Services to Comprehend & Interact in Human Language
For many AI services, it is critical to be able to comprehend human language and even converse in it with human users. So far, advances in natural language processing (NLP) powered with “sub-symbolic” machine learning based on deep neural networks allows us to solve multiple tasks like machine translation, classification, and emotion recognition.
However, using these approaches requires enormous amount of training. Additionally, there are increasing legal restrictions in particular applications due to recent regulations, making current solutions unviable.
The ultimate goal for these industry initiatives is to allow humans and AI to interact fluently in a common language.
I thought a data subject became a data object by simply removing the top layer, name, rank and serial number so to speak… Is that not satisfying the right to be forgotten whilst still making ml curated data available for ai? The use of blockchain would keep the process trustless…
Unsure how this relates to the topic. Though on the subject you mention the idea of stripping pii and hoping others won’t infer using broader data is naive. Example: If a social network bought anonimised data from a hospital but used their own location data to make linkage to a subject with credible certainty. Object and subject data distinction may well be outdated, though I find gdpr an impressive effort
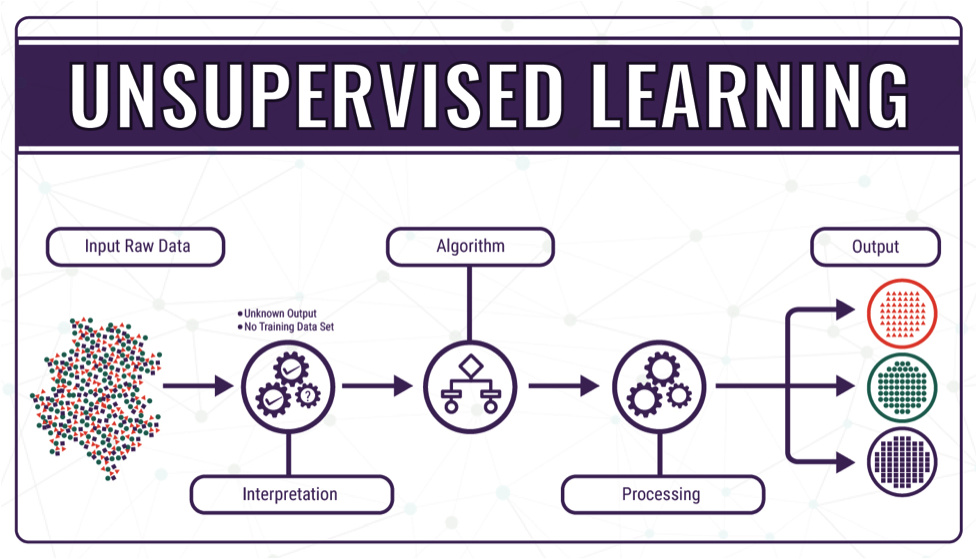
Am I right in thinking that Unsupervised Learning still requires some human input to identify the classes (rather than each instance) ?
I’m trying to figure out how my project, which uses humans to annotate data, can still be relevant when using Unsupervised Learning. At the moment we label/tag everything.
Hey AndyMicrowork - if you’re annotating your data using humans then it’s generally still considered supervised learning. However, there is a lot of interest in various areas of machine learning where people train unsupervised or weakly-supervised for 90% of the problem, and on huge amounts of data, but then fine tune the model on a smaller set of labelled data.
In energy deregulation, our number one obstacle was leveraging revenue/investment grade data from desparate nodes/agents to sustain the vision of the collective industry. Literally, in the beginning things changed on a daily basis.
We used a term “Settlement Quality Meter Data” to describe the data set that shall be sent to authorities having jurisdiction (shall is purposefully used to emphasize the need to adhere to policy and standard).
In my crude comparison of industry, I coined the term "SQUAID" for the lack of a better term. Settlement Quality AI Data (SQAID). Please don’t attack me here…lol!
Is there a term for various “settlement” quality AI data other than contract?! Is there a Glossary of Terms that a novice might use to be on the same page with SingularityNET?!
For instance, what do you call an “AI perpetuated upgrade algorithm” that will circumvent the need for any future for human intervention. A “machine learning patch”?!
I’d like to learn. I’d like to contribute to the community.
Re: For instance, what do you call an “AI perpetuated upgrade algorithm” that will circumvent the need for any future for human intervention. A “machine learning patch”?!
For the rest of “learnings”, there could be different forms, overlapping in practical cases/solutions:
supervised - learning labeled/tagged corpora or having “grounding” annotation supplied to each
reinforcement - when you use unlabeled/untagged corpora or unannotated inputs but every output is supplied with reinforcing feedback so the learner adapts
unsupervised - when you have neither tags/labels nor grounding annotations nor reinforcing feedback
With unsupervised option, you still may have couple relaxations:
a) use unlabeled/untagged yet “controlled” corpora, so the contents of the corpora are prepared by instructor in order with some idea how the learning process should take place (like you give school-level books to children before you you give university-level books to them)
b) use self-reinforcing learning in “reinforcing” environment, where the learner can follow “try-and-fail” approach and self-reinforce themselves in respect to some goal
Goal posing for the latter is another can of worms…
Oh dear, I didn’t explain myself very well. It’s not your comment that I found naive Joe, but the concept that by removing some data items that humans might recognize that the data is suddenly anonymous. It’s a concept that is used in a lot of privacy standards, etc. but for my money is risky. Apologies if that came across wrongly.
OpenCog is umbrella project for almost 40 different sub-projects and provides suite of tools for building AGI: OpenCog · GitHub
SingularityNET is umbrella project for almost 20 different sub-projects and provides suite of tools to create decentralised AGI: SingularityNET · GitHub
NLP is wide domain which includes large part of universe, and the ULL is part of universe called NLP, it is also part of smaller universe called “OpenCog NLP”
That is, if you want magic formula, then:
ULL = OpenCog Framework + OpenCog Link Grammar + SingluarityNet Language Leanring
@cassio and @bengoertzel may correct me if I am missing part of the larger story